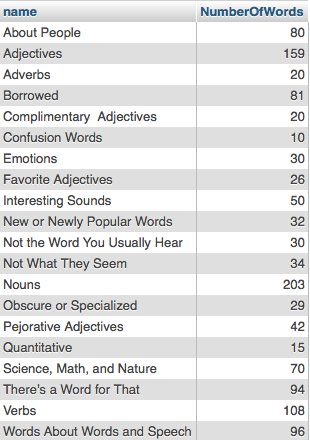
I track visitors to my app and CD pages by storing each visit in a log file. I can get the total visits for CDs with this code. I use a RIGHT OUTER JOIN because I only want to count visits for CDs. They are in the product table, so if I use a RIGHT OUTER JOIN I will not get any rows that are from the apps.
SELECT product.name, product_id, COUNT(*) FROM log
RIGHT OUTER JOIN product
ON product.id = log.product_id
GROUP BY product_id
ORDER BY COUNT(*) DESC
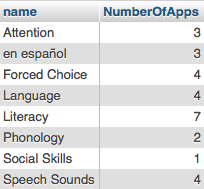
Total visits for apps is from this code. I need to subtract 100 from the product_id because apps and CDs both start their ids with 1. To differentiate them, I add 100 to apps before putting them into the log table.
SELECT app.name, product_id, COUNT(*) FROM log
RIGHT OUTER JOIN app
ON app.id = (log.product_id - 100)
GROUP BY product_id
ORDER BY COUNT(*) DESC
To combine the two results into one table, I use a UNION. I renamed the first column of each table so that combined table will display the column header as name. I want to sort on COUNT(*) but that isn’t available in the UNION so I rename COUNT(*) to count. Now I have a named column in the resulting table and I can sort on it.
SELECT app.name AS name, product_id, COUNT(*) AS count
FROM log
RIGHT OUTER JOIN app ON app.id = ( log.product_id -100 )
GROUP BY product_id
UNION
SELECT product.name AS name, product_id, COUNT(*) AS count
FROM log
RIGHT OUTER JOIN product ON product.id = log.product_id
GROUP BY product_id
ORDER BY count DESC
One caveat. Because I used RIGHT OUTER JOINs, there may be rows in the log table that were not summarized. In fact there are several from the landing page that are not counted.