Great post by Eddie Woo on how to maximize your learning.
Processing bad email addresses in our customer list.
Back in 2014 I wrote a post about processing returned email and enough has changed that the advice is no longer relevant.
I use Apple’s email client to send and receive mail and this time around I created rules for dealing with the remove requests, auto replies, and bad addresses. I don’t get many remove requests so I handle them individually. Likewise, the automated replies usually are out of office or moved to a new location so they get manual treatment as well.
This time around I got 12,002 failures—although the actual number is much lower because servers will give 24, 48, and 72 hour notices as well when they can’t deliver the mail. Deleting the 7,747 warning messages yields 4,255. I used three rules to put the returned mail into a Failure mailbox.
Subject begins with Warning: message
Subject begins with Undeliverable
Subject begins with Mail delivery failed:
This caught most of them. I then selected all of the messages and printed them to a PDF file. Mail does not warn you that it will only print 300 pages so if you don’t have a lot of failures you can select groups of messages and make sure that there are fewer than 300 pages in the group. My computer is old so it also is slow to delete messages. So you need to be patient.
If you can get the messages into a PDF file you can open it in Preview, select all and then use the BBEdit feature Process Lines Containing to first extract lines with @ and then remove ones with your domain. From there it was just a matter of getting rid of things like retry timeout exceeded, Final-Recipient: rfc822;, and Status: 5.0.0 by doing a simple find and replace.
Getting rid of the last group took a bit of grepping since I wanted to get rid of everything before the “<” e.g.
To: "Alice Foxwood" <AliceFoxwood@yahoo.com>
*.<
cd /Users/jscarry/Desktop/Mail
grep -R 'AliceFoxwood@yahoo.com' .
cd ./V7/06676897-0872-4618-9225-222A5281A236/Failure.mbox/69AC0518-E9C8-4B54-ADD0-2A0B676267B4/Data/
grep -R "@" . > ~/Desktop/failure.txt
There are lots of duplicates in the list since so I sorted the lines and then removed duplicates. That left me with 4255 bad addresses which I then imported to my bad address table. That’s more than the 4,116 failure emails because some of the failure messages had an internal email address e.g. AliceFoxwood@baylor0.mail.onmicrosoft.com.
Sending Bulk Email
I have a new product that I want to notify my customers of and since it has been a while since I last sent an email blast and I have moved to a new server, I wanted to make sure I was conforming to the latest best practices. And when they sign up I want to make sure that confirmation and billing emails get delivered.
Return Path
The first thing I noticed is that my Return-path and envelope-from were set to the server name rather than the domain of the user that I was sending the email from. There is a way to configure Exim4 to automatically use the domain of the user when sending email, but I couldn’t figure out how to do it. I found this article that explains how to change it. However, since all of the mail I send from that server comes from the same domain, I fixed the problem by changing the /etc/mailname file so that it has the sending domain rather than the server’s domain.
I also updated my SSL config with certbot to set up mail.wellgolly.com as part of the SSL configuration. You need to do this separately from the website using sudo certbot certonly --standalone -d mail.wellgolly.com. However, since I changed the sending domain from mail.wellgolly.com to wellgolly.com this didn’t matter in the end for my bulk email but since my confirmation and billing emails still send out from mail.wellgolly.com. (I’m working on figuring out why they do that—the code uses PHP and was written by my guys 25 years ago, so I haven’t quite figured it out yet.)
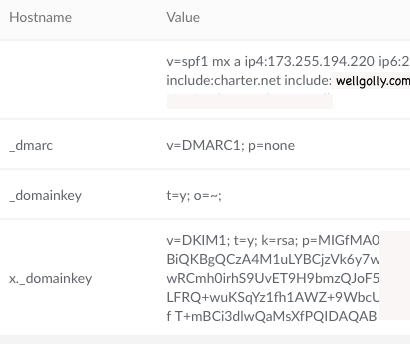
Then I added a text file to my DNS. This spf file is not supposed to have a HOSTNAME label. The validator couldn’t find the spf file when it had a label but finds it when I removed the label.
v=spf1 mx a ip4:173.255.194.220 ip6:2600:3c00::f03c:91ff:fe70:bc93 include:charter.net include:wellgolly.com include:mail.wellgolly.com -all
Note that you include all of the servers that you use to send mail. In my case I use an ISP to send mail from my computers and wellgolly.com for the bulk email. As I mentioned earlier, I still haven’t figured out why my order confirmation emails use mail.wellgolly.com so I put that in as well. If you send email from your phone, you’d include that server as well.
DKIM
I found these two links that were useful for setting up DKIM with Exim4. myleen and a concise explanation from Mike Pultz.
remote_smtp:
debug_print = "T: remote_smtp for $local_part@$domain"
driver = smtp
dkim_domain = wellgolly.com
dkim_selector = x
dkim_private_key = /etc/exim4/dkim.private.key
dkim_canon = relaxedThe forum post from myleen says that you can use dkim_domain = ${lc:${domain:$h_from:}} but I didn’t try it.
One thing that I forgot was that the my Exim configuration on my machine is not set up in separate files but is in one large config file, exim4.conf.template. To have the changes take effect you need to run sudo update-exim4.conf and then restart Exim.
Notice that the line dkim_selector = x. The x can be anything but when you add the DKIM key you need to use the same label. In my case, x._domainkey.
Generate the public and private keys as described in the article and add two TXT files
x._domainkey.example.com. TXT v=DKIM1; t=y; k=rsa; p=<public key>
_domainkey.example.com. t=y; o=~;
These are the TXT files I created so that the validator is happy.
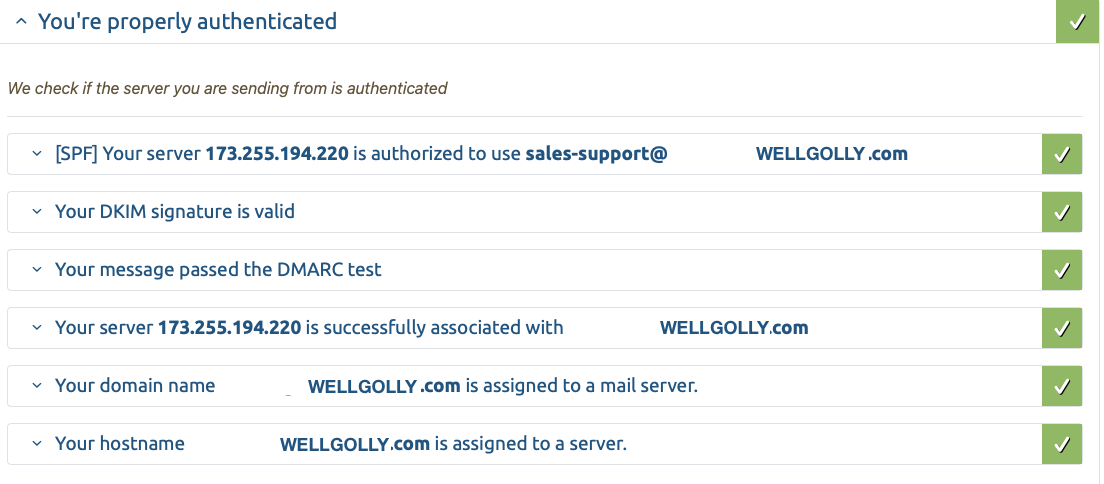
Verification
You can send an email to check-auth@verifier.port25.com and it will respond with cryptic summary of results. This is good if you understand all the terms and how to fix things. I didn’t, so I used Mail Tester to check my mailings. It’s free for the first three but since I was fixing and testing based on their feedback I ponied up the 25€ ($27.50 with conversion fee of .15) and got 25 tests.
Make sure that Exim has permission to read the dkim.private.key file. This caused some validation errors. I don’t know who the user is that is sending the mail, so I couldn’t add them to a group. What I did instead was make everyone able to read the file using chmod o+rx.
Reverse DNS
I was getting this error:
Your IP address 173.255.194.220 is associated with the domain wellgolly.com.
Nevertheless your message appears to be sent from mail.wellgolly.com.
You may want to change the host name of your server to wellgolly.com.So to fix this I edited /etc/hosts to remove the mail. prefix.
List Unsubscribe
This is recommended for newsletters so I added it. I can’t see it in the mail readers that I use, but it got rid of some negative scoring on the validator so I added it. I think Spark uses it to indicate that the message is a Newsletter.
Unsubscribe
List-Unsubscribe: <mailto: unsubrequests@exampledomain.com?subject=unsubscribe>, <http://www.exampledomain.com/unsubscribe.html>
This is what the mail validator says now and I score 10/10. Unfortunately, that didn’t prevent Gmail from marking my email as spam, but at least it didn’t get rejected entirely.

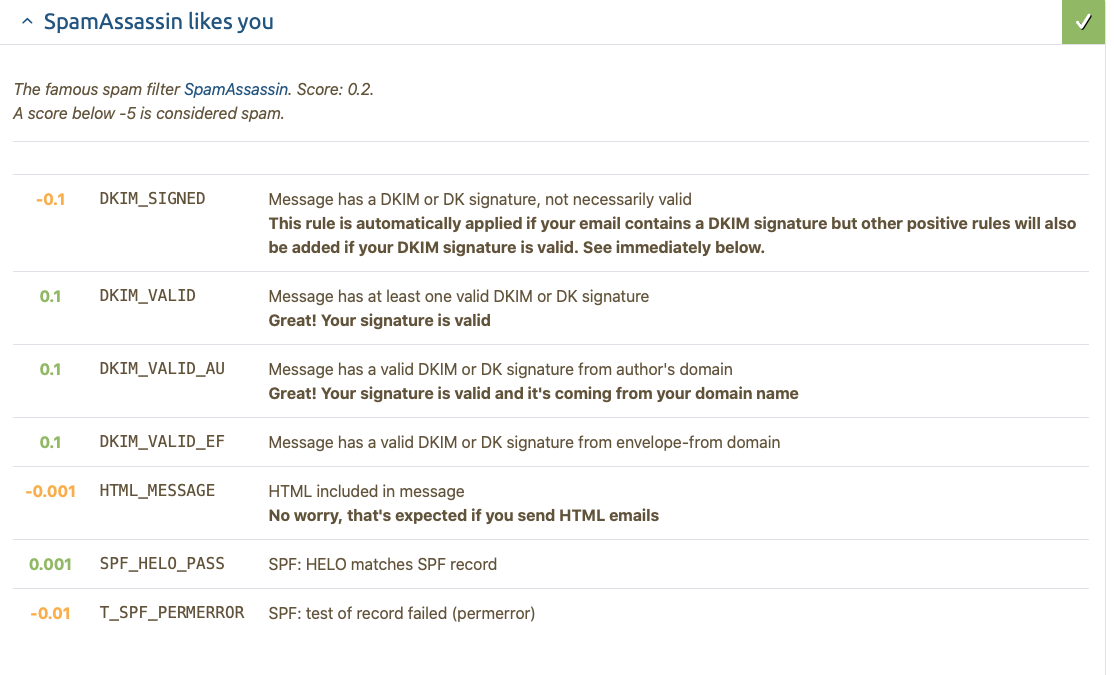
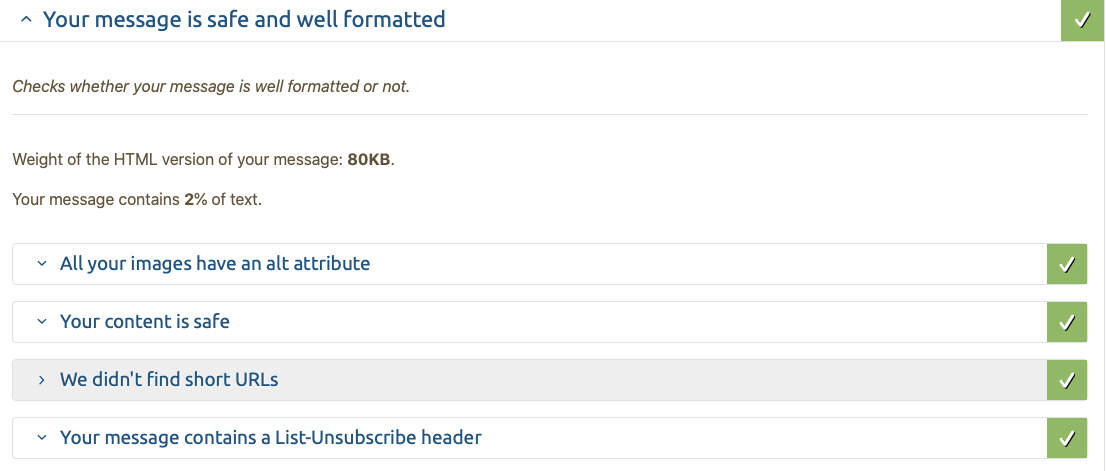
I couldn’t track down what the T_SPF_PERMERROR means but it doesn’t seem to have any effect on my score.
One thing that paradoxically did have an effect on my score was a ratio of text to graphics that was too high. I added a paragraph of text and that issue was resolved.
The results from verifier.port25.com are encouraging as well. Unlike Mail Tester, they don’t tell you how to fix the problems or even really what the results mean. They are free however, and now that I know a bit about what everything means, I’ll probably use them for checking things when I make changes.
==========================================================
Summary of Results
==========================================================
SPF check: pass
"iprev" check: pass
DKIM check: pass
SpamAssassin check: ham
==========================================================
Details:
==========================================================
HELO hostname: wellgolly.com
Source IP: 2600:3c00::f03c:91ff:fe70:bc93
mail-from: sales-support@wellgolly.com
----------------------------------------------------------
SPF check details:
----------------------------------------------------------
Result: pass
ID(s) verified: smtp.mailfrom=sales-support@wellgolly.com
DNS record(s):
wellgolly.com. 300 IN TXT "v=spf1 mx a ip4:173.255.194.220 ip6:2600:3c00::f03c:91ff:fe70:bc93 include:charter.net include:wellgolly.com include:mail.wellgolly.com-all"
wellgolly.com. 300 IN MX 1 mail.wellgolly.com.
mail.wellgolly.com. 300 IN AAAA 2600:3c00::f03c:91ff:fe70:bc93
----------------------------------------------------------
"iprev" check details:
----------------------------------------------------------
Result: pass (matches wellgolly.com)
ID(s) verified: policy.iprev="2600:3c00::f03c:91ff:fe70:bc93"
DNS record(s):
3.9.c.b.0.7.e.f.f.f.1.9.c.3.0.f.0.0.0.0.0.0.0.0.0.0.c.3.0.0.6.2.ip6.arpa. 300 IN PTR wellgolly.com.
wellgolly.com. 300 IN AAAA 2600:3c00::f03c:91ff:fe70:bc93
----------------------------------------------------------
DKIM check details:
----------------------------------------------------------
Result: pass (matches From: sales-support@wellgolly.com)
ID(s) verified: header.d=wellgolly.comThe simple verifier has some options that you can find at their website. I also used it to check what’s happening with my other mail by sending a command-line email.
/usr/sbin/exim -v check-auth@verifier.port25.com
From: sales-support@wellgolly.com
To: check-auth@verifier.port25.com
Subject: DKIM Test
test messageIn case you’ve forgotten, when you send a multi-line command you terminate it with ctl-d.
The Result
I sent out my mass mailing to customers today and, unlike previous years, I did not get any bounces for missing SPF record, line length exceeded, or spam filters. So the couple of days figuring this out was worth it.
I did get a lot of bounces since many people do not keep the same address forever like I do. Many of them are from schools and companies so it makes sense that the email address is deactivated after a while when employees leave. Lots of bounces for mailbox full so most of them are also probably old email addresses.
I dumped all of the undeliverable mail into a file so I can make a list of bad addresses and the first one in the list also has a bunch of diagnostic stuff in it. An interesting bit was this section:
X-Barracuda-Spam-Score: 0.62
X-Barracuda-Spam-Status: No, SCORE=0.62 using per-user scores of TAG_LEVEL=1000.0 QUARANTINE_LEVEL=1000.0 KILL_LEVEL=5.0 tests=ANY_BOUNCE_MESSAGE, BOUNCE_MESSAGE, BSF_SC0_SA074b, BSF_SC0_SA590, EMPTY_ENV_FROM, NO_REAL_NAME, SH_BIG5_05413_BODY_104
X-Barracuda-Spam-Report: Code version 3.2, rules version 3.2.3.83021
Rule breakdown below
pts rule name description
---- ---------------------- --------------------------------------------------
0.00 EMPTY_ENV_FROM Empty Envelope From Address
0.00 NO_REAL_NAME From: does not include a real name
0.21 SH_BIG5_05413_BODY_104 BODY: Body: contain "UNSUBSCRIBE"
0.20 BSF_SC0_SA590 Custom Rule SA590
0.20 BSF_SC0_SA074b Custom Rule SA074b
0.00 BOUNCE_MESSAGE MTA bounce message
0.00 ANY_BOUNCE_MESSAGE Message is some kind of bounce message
According to the Barracuda website my score if .62 is great since The score ranges from 0 (definitely not spam) to 10 or higher (definitely spam). That program is fairly popular and there were 52 other messages that I got back 35 had a score of 0, 6 had a score of 1.09, two had a score of 2.02 and the rest were between .21 and .91. I’m not sure I can do anything about the high scores since the report doesn’t make a lot of sense to me. My embedded URLs use HTTPS and are really short—just the domain name followed by exercises/overview.html. Most of the points come from their custom rules so there’s not much I can do about that.
Rule breakdown below
pts rule name description
---- ---------------------- --------------------------------------------------
0.00 NORMAL_HTTP_TO_IP Uses a dotted-decimal IP address in URL
0.00 NO_REAL_NAME From: does not include a real name
0.00 MIME_BOUND_MANY_HEX Spam tool pattern in MIME boundary
0.00 EMPTY_ENV_FROM Empty Envelope From Address
0.32 URI_HEX URI: URI hostname has long hexadecimal sequence
0.00 IP_LINK_PLUS URI: Dotted-decimal IP address followed by CGI
0.50 WEIRD_PORT URI: Uses non-standard port number for HTTP
0.00 HTML_MESSAGE BODY: HTML included in message
0.20 BSF_SC0_SA590 Custom Rule SA590
0.50 BSF_RULE7568M Custom Rule 7568M
0.50 BSF_RULE_7582B Custom Rule 7582B
0.00 BOUNCE_MESSAGE MTA bounce message
0.00 ANY_BOUNCE_MESSAGE Message is some kind of bounce message>/code>
There were only five messages checked with SpamAssassin and this was the result:
<code>
X-Spam-Status: No, score=0.0 required=9.9 tests=HTML_MESSAGE
autolearn=disabled version=3.3.2
X-Spam-Checker-Version: SpamAssassin 3.3.2 (2011-06-06) One message had this report which makes no sense to me, but maybe it will be useful to someone else.
X-ENA-MailScanner-SpamCheck: not spam, SpamAssassin (not cached, score=3.554,
required 4, BAYES_00 -2.20, DATE_IN_PAST_06_12 1.54,
DKIM_SIGNED 0.10, DKIM_VALID -0.10, DKIM_VALID_AU -0.10,
DKIM_VALID_EF -0.10, DMARC_PASS -0.00, ENA_BAD_OPTOUT 2.20,
ENA_BAD_OPTOUT5 0.00, ENA_BAYES_OFFSET 2.20, HTML_MESSAGE 0.00,
ENA_BAD_OPTOUT5 0.00, ENA_BAYES_OFFSET 2.20, HTML_MESSAGE 0.00,
SPF_HELO_PASS -0.20, SPF_PERMERROR 0.20, T_SPF_PERMERROR 0.01)There were 36 of these:
X-Forefront-Antispam-Report:
CIP:134.197.10.234;CTRY:US;LANG:en;SCL:1;SRV:;IPV:NLI;SFV:NSPM;H:UC-Exchange1.unr.edu;PTR:InfoDomainNonexistent;CAT:NONE;SFTY:;SFS:(50650200002)(4636009)(136003)(396003)(346002)(376002)(39860400002)(1930700014)(46966005)(30864003)(78352004)(42882007)(336012)(26005)(7696005)(498600001)(45080400002)(2876002)(31686004)(8936002)(8676002)(2906002)(83380400001)(6916009)(55016002)(786003)(316002)(31696002)(82310400002)(70586007)(70206006)(66576008)(82740400003)(956004)(47076004)(81166007)(5660300002)(356005)(53652003)(559001)(579004)(299355004);DIR:OUT;SFP:1501;You can try to decipher it at the Microsoft website but I think the good part for me is CAT:NONE; since all of the listed categories are bad and NONE appears to be the default that indicates that the message is not spam.
One of the things that you need to do to keep off the spam lists is remove old email addresses. I don’t plan on sending bulk emails to my customers very often but if I do I want to stay off the spammer list. So I created a list of bad addresses. The first thing I did was to search for X-Failed-Recipients:. This provided me with a clean list of 86% of the bounces.
I then looked for To: ". This gave me more lines than bounced messages but by filtering out every line that didn’t end in >, sorting the remainder and removing duplicate lines, I got it down to one line per address. 94% of the bounces.
Combining the two gives me slightly fewer addresses than using the To: " method alone. This probably happened because I had people in the database multiple times with slightly different name fields.
There were a handful of Unknown address error messages that didn’t fit any pattern for automatic filtering. They were only 1% of the total so I cleaned them up by hand. Nothing else popped out to me so I think I’ll leave it at that.
git Commands I Use
I started using git with my first Apple app because it was built into Xcode and one of the first lessons in the Stanford Xcode class recommended that we use it. I never used the branching features, since I’m the only one working on the code, but I frequently made use of the lookback features so I could roll back code that didn’t work or grab code that I had discarded but found out that I needed. So I basically used it for journaling.
Most of the websites that I work on don’t have lots of active users so when I want to make an update or something breaks, I just work on a copy or on the live files. However, I recently started a website that has active users and rather than only working in the site at night or making sure no one was using it before potentially breaking it, I decided to make a beta subdomain as I explained in some recent PHP-related posts. As long as I don’t mess with the database I can break whatever I want and it doesn’t affect users.
At first I thought that I’d use rsync to sync the two but git seems to work fine. The only problem is if I fix a small bug on the live site then I have trouble getting the new stuff to synchronize. I suppose I could figure out how to resolve differences, but an easier way is just to force the live site to match the beta site. Since they are on the same server, it doesn’t take any time to synchronize.
git fetch --all
git reset --hard origin/masterThe normal way to sync when I haven’t made any changes is just:
git pull origin masterI also keep a copy as backup on my laptop with the same code.
// Do this once to establish the origin
git remote add origin "ssh://g@wellgolly.com/www/beta/exercises/.git"
// Do this when you want to synchronize
git pull origin masterPHP include paths
One of the nice things about PHP is that it is easy to write one common file for things like headers and footers and then include that file in every page that you publish. For simple sites, it is easy, you just include a line like this in as the first line your code.
<?php
require_once('header.inc'); ?>where the file is something like this:
<!doctype html>
<html lang="en-US">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="copyright" content="Copyright ©<?php echo $now; ?> Well Golly.com" />
<meta name="rating" content="general" />
<meta name="robots" content="all" />
<meta name="description" lang="en" content="<?php echo $meta_description; ?>"/>
<meta name="keywords" content="<?php echo $meta_keywords; ?>" />
<meta name="robots" lang="en" content="index follow" />
<link rel="icon" type="image/png" href="./common_images/favicon.png" />
<link rel="apple-touch-icon" href="./common_images/apple-touch-icon.png"/>
<link rel="stylesheet" href="/css/pure-min.css">
<title><?php echo $page_title; ?></title>
</head>Once you have the basic file in place, you can start embellishing it. Note that I refer to several PHP variables. If you examine the source for this page, you see that it is copied literally into the HTML source and a few variables that I previously defined take on their values. These are defined in a file that I call set_variables.inc.
<?php
$day = date("Y-m-d",strtotime("now"));
$today = date("Y-m-d");
$nowDate = date('Y'); // Used for copyright notices in the header tag and in the footer.
// Here is where you provide information about your site.
$site_name = "Well Golly";
$site_shortName = "Well Golly";
$site_URL = "https://Well Golly.com";
$copyright_text = "© Copyright $nowDate $site_name";
$footer_text = "© Copyright $nowDate <a href=\"{$site_URL}\">$site_name</a> $site_address $site_phone";
$keywords = "$site_name"; // Separate terms with commas
$description = "$site_name web-based exercises.";
$meta_description = 'Well Golly Exercises.';
$meta_keywords = 'products, apps, software';
$page_title = "$site_name Exercises";
?>Note that this file starts with because none of the information on the page is HTML. This file defines variables that I use in other files to generate HTML.
One thing that is confusing at first is how PHP finds the included files. If you just use the file name in the call, then PHP looks in the current directory for the file. PHP uses Unix conventions, so if you are in a subdirectory and want to call a file one level above, you would preface the file name with ../ e.g.
<?php
require_once('../header.inc'); ?>Likewise, two levels up is ../../ and two levels up then down a level is ../../directory. This can get confusing after a while so what most people do is create a directory in the document root and put include files that are used throughout the site in it. Here’s an example of my include.php file for a site.
agreement.inc
check_login.inc
footer_menu.inc
footer.inc
header_logo.inc
header_menu.inc
header.inc
login_validation.inc
set_variables.inc
signup_confirmation.inc
signup_form.inc
signup_updateDB.inc
signup_validation.inc
timeZones.incRemembering to put the correct number of ../s can be tiresome so what I do is define a search path and put it in my php.ini file. I don’t remember precisely what it looks like, but this line from my /var/log/php_error.log file tells me where PHP was looking for a file that it can’t find.
PHP Fatal error: require_once(): Failed opening required './include.php/header_menu.inc' (include_path='.:/usr/share/php5:/usr/share/php:./include.php:..:../include.php:../../include.php:../../../include.php')I basically says to look first in the current directory . , then in the PHP provided directories, then in the next level up, etc. If you want to override the search path you can just specify where PHP should look for the file. For example, in the page where users interact with your app, you may not want all of the normal branding and menu choices. Create a simple header file and access it directly by specifying the path.
<?php
require_once('./header.inc'); ?>You can do the same thing for CSS and javascript. I do this for all of my apps since there is some common javascript but much of it is specific to an app and I don”t want the code to get confused because I used a function name that has a different input and output in other apps. Plus there is less code being downloaded so the page loads faster.
Where it gets tricky is when you start thinking that PHP starts looking in the document root for files and images when in fact it starts looking in the root of the server as defined in your Apache2 conf file. In my case it is /srv/www.
So if you want to include an image in your logo, you might put it in /common_images in the document root. However, if you call it using <img src='/common_images/logo.png' alt=logo' /> PHP won’t find it because it will be looking in /srv/www//common_images/logo.png. Remove the first slash and you are good to go—if you are calling the images from the same level as common_images. You could add the path to your php.ini file, but I have a bunch of folders that I use where I would have to do that. An easier way is to use PHP server variables. In the example below, I have already defined the $site_URL in my set_varialbles.inc file and use a built-in PHP function, explode, to get the filename of the directory where my common_images directory is located. So no matter how far down the directory tree I am, I can still get the location where the logo is located—https://beta.wellgolly.com/exercises/common_images.
<div id="header" class="pure-g">
<div class="pure-u-1 pure-u-lg-1-2">
<a href="<?php echo $site_URL ?>">
<?php
$curRoot = explode("/", $_SERVER['REQUEST_URI']);
?>
<img class="pure-img-responsive" src="<?php echo "{$site_URL}/{$curRoot[1]}" ?>/common_images/wg_header.png" alt="Header">
</a>
</div>
</div>